

Case Study
1. Introduction
1.1 Tailslide
Tailslide is an open-source, lightweight, self-hosted feature flag management solution designed for organizations with a microservices architecture to easily and safely deploy new backend features with built-in circuit-breaking. Tailslide monitors the performance of feature flags and leverages a customizable circuit-breaking pattern to toggle off problematic features and direct users to a pre-defined fallback service or feature. If circuits trip, indicating that features are not working as intended - developers are immediately notified via a Slack notification, so they can respond appropriately. Tailslide speeds up the deployment cycle without sacrificing reliability.
Using Tailslide, developers can perform "dark launches" - allowing for experimentation of new features in a live production environment, where only internal test accounts or beta users are served the new feature. Tailslide also allows for the safe and gradual rollout of individual features to a subset of the user base, with the ability to easily ramp up, ramp down or shut off all traffic to a specified feature.
1.2 Deployment and Feature Release

To first understand the “why” behind feature flags, it’s important to first understand the context surrounding feature flags. Let’s first describe deployment and feature release, before discussing the traditional software release cycle and why software teams should strive toward more frequent deployments.
Deployment is the process of distributing code from a development or staging environment into a production environment [1].
Feature Release refers to making features in deployed code available to users [1].
As Tailslide’s focus is on server-side feature flags, in this write up we will use feature to refer to any new functionality or service being developed on the backend of a web application.
1.3 Traditional Software Release Cycle
In a traditional software release cycle, feature release occurs simultaneously with deployment. Once code is deployed, all users will receive the features within that feature release. Although new features may appear to work in a staging environment, unexpected issues often arise in production - such as when a server fails to handle higher-than-expected user traffic.
The downside of releasing features alongside deployment is that when features break, developers must scramble to deploy hotfixes on top of the problematic deployment or roll back the deployment altogether. Even if there is only one offending feature, the entire deployment could have to be rolled back.
This leads to unpredictable repair wait times or extended service downtime, negatively impacting both the development team and the end user. The tight coupling between deployment and feature release means that developers have little control over the active state of their new features after deployment. As a result, traditional deployment and feature release processes contribute to long software release cycles with negative consequences [2].
1.4 Benefits of Frequent Deployment
Delivering new features in a timely and reliable manner is critical for the success of a software company. This often requires efficient software development teams capable of frequently deploying new features while guaranteeing service uptime for end users [3]. One way to expedite the deployment process is by allowing teams to safely deploy into production on demand, allowing them to experiment and see how their code behaves in a production environment.
In order to perform this safely, two criteria must be satisfied:
- First, the impact of deployments on end users should be controllable, so that only target users receive the new features without affecting the experience of regular users.
- Second, the deployment process should have a low mean time to recovery (MTTR) [4] so that service outages from failed deployment do not impact business operations.
1.4.1 Deployment Flexibility
To meet these criteria, it is important to separate deployment from feature release. Feature flags are one way to separate deployment from feature release. Feature flags work by abstracting feature releases as conditionals in the application code. This means developers introduce feature release logic to target which users receive the new features and control the impact radius of their new features. This abstraction allows developers to instantly shut off all traffic to problematic new features without needing additional hotfixes or deployment rollbacks.
1.4.2 Deployment Reliability
Deployment reliability is just as important as frequency. A tool that implements the well-established circuit breaking pattern can automatically turn new features off when problems arise, thus lowering MTTR. This automatic fail-safe helps to reduce the burden of monitoring the performance of new features on development teams, allowing them to safely release code into production without worrying about service interruptions. They can rest assured that fallbacks are in place when new features fail.
1.4.3 Deployment Feedback
Real-world feedback is especially informative in a microservices architecture, where testing the interactions among microservices in staging environments can be challenging and time-consuming. Allowing new features to fail early but safely in the production environment enables developers to observe how their systems behave in unexpected production scenarios that simulated tests cannot anticipate, such as unexpectedly high traffic, infrastructure problems, or unpredictable user behavior. Testing in production is an invaluable resource for developers to learn from, in order to iterate and improve on new features quickly.
2. Hypothetical
To illustrate how feature flags can improve deployment, let’s describe the challenges that a hypothetical company, Healthbar, faced before discovering feature flags as a deployment strategy.

Healthbar is a startup that provides platform-as-a-service (PaaS) related to information technology for hospitals, medical and healthcare companies. Healthbar uses a microservices architecture. Due to the severe consequences of service downtime for its customers, Healthbar takes precautions to avoid widespread service blackouts. Healthbar wants to ensure that its customers are being serviced at all times. Healthbar’s processes include deploying code in automated test environments and a robust code review approval process, involving multiple rounds of approval amongst developers, testers, and managers. Although these safeguards have been effective in minimizing service blackouts, they have slowed deployment, and teams often spend over a month between deployments.
Healthbar’s management wants to better serve customer needs as more companies enter the space. They encourage engineering teams to release new features faster, to retain and grow existing market share. Currently, using the traditional deployment strategy greatly limits the teams’ progress.
2.1 Canary Deployment
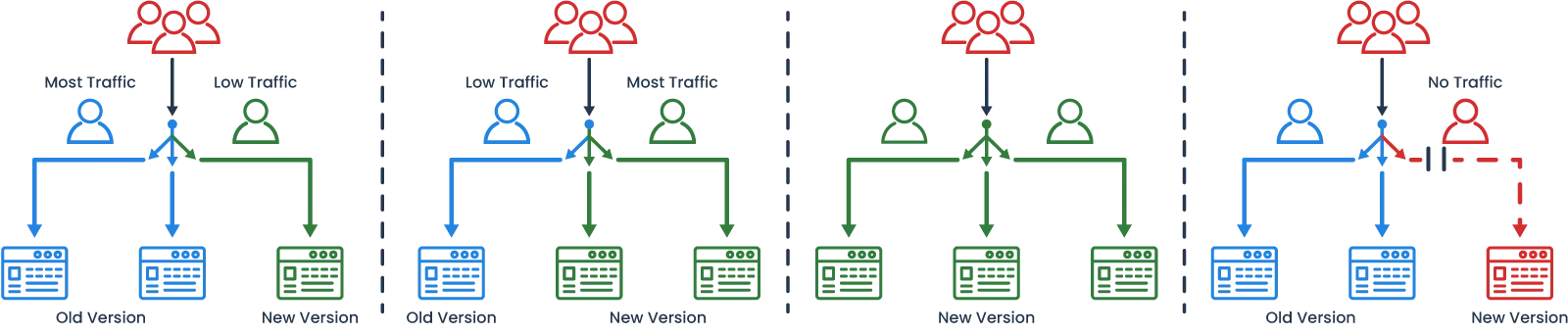
Recently, Healthbar discovered Canary Deployment, a deployment strategy that releases an application or service incrementally to a subset of users, before rolling out the change to all users if no issues arise [5]. With canary deployments, two versions of an application are deployed onto two separate production environments: the latest production release, and the canary version (version with new features). A load balancer is used to direct some traffic to the canary, with the remaining traffic going to the latest release. If no issues occur, the traffic directed to the canary increases, until all users are routed to the canary. If problems arise with the canary - the rollback strategy is simply to reroute all users back to the current version, until problems with the canary have been fixed. With Canary Deployments, the determination of which version a user is served occurs at the infrastructure layer, via the load balancer.
2.1.1 Benefits of Canary Deployments
Canary Deployments help Healthbar to increase its deployment frequency and allow them to safely test its new services in production. By controlling the traffic to a canary to only a small subset of users with a gradual rollout, Healthbar reduces the risk of a problematic deployment leading to a widespread service blackout that affects all users. Healthbar loosens some of its stringent approval processes, resulting in more frequent deployments. Frequent deployment means smaller changes in each deployment, fewer things that may break, and fewer checklists for teams to cross off or monitor. Management is happy to see an increase in productivity. With the new features becoming more mature, it wants the teams to integrate those new features into core business offerings.
2.1.2 Shortcomings of Canary Deployment
Canary Deployments still suffer from a tight coupling of deployment and feature release, a similar limitation faced in a traditional software release. Developers lack the ability to control the state of individual new features after deployment. If the canary consists of multiple new features, but only one non-essential feature is problematic, there is no way to switch off traffic routed towards only that problematic feature. Instead, they must reroute all users from the canary back to the existing version.

Another shortfall of canary deployments arises in feature integration. As the number of features involved in integration tasks increases, the number of canary deployments also grows. This is because experimenting with different combinations of features, requires multiple deployments and additional infrastructures for hosting those deployments, increasing both complexity and costs of deployment.
For instance, a potential solution may involve any combination of Features A, B, and C, all of which would require their own separate canary deployment for testing. Ultimately, due to the nature of microservices architectures, testing the integration of new features in production is the only way to gain assurance that features are functioning correctly under real-world conditions, such as high traffic load, infrastructure problems, and unpredictable user behavior.
With Healthbar’s limited resources, the developers need another deployment strategy that offers ease of feature integration in a single deployment, the granular control to selectively toggle individual features on or off without entire version rollback, and the ability to safely and reliably test in production with automatic fail-safes.
2.2 Feature Flags
2.2.1 Benefits of Feature Flags

With further research and discussion within Healthbar teams, they came up with Feature Flags. Feature flags decouple feature release from infrastructure [6]. At its simplest, feature flags embed conditional logic into applications which allow developers to dynamically control the on or off state of individual features at runtime. Fundamentally, feature flags allow developers to decouple deployment from feature release. Deployment is now only about moving code into production, and feature release solely depends on runtime logic. Since feature flags evaluate feature release at the application layer, developers are free to test different combinations of their features in their feature integration tasks with just a single deployment.
With feature flags, the developers only need to make a single deployment that covers both the new and current features on the same infrastructure. The determination of which version a user is served occurs at the application layer, based on the runtime logic. In this way, deployment is tied to the underlying infrastructure, and feature release is manipulated by server application logic.
2.2.2 Additional Feature Flags Capabilities
Developers at Healthbar identify additional elements they are seeking in a feature flag solution in order to safely and reliably test in production, as their features move through varying levels of maturity.
- Targeted Testing - In the early stages, the developers want the ability to expose specific internal test users with the new features, without affecting regular users. In addition, developers want granular control over which specific features to toggle on or off in order to test different combinations of features. While a canary deployment can target internal testers, the full feature set must either be on or off, which limits developers’ ability to test new features.
- Gradual Rollout - From their experience with canary deployments, the developers now also want the power to safely and gradually roll out an individual feature to a subset of users, and slowly expose it to the entire user base if no issues arise. This is similar to the rollout strategy for a canary deployment, except the rollout control is finer-grained, and occurs at the individual feature level.
- Automated Failsafe - Once ready for release to the entire user-base, Healthbar’s priority remains focussed on the reduction of widespread service blackout. If calls to a new feature or service fail unexpectedly - perhaps slower response times due to higher-than-usual traffic - Healthbar would like an automated fault-tolerant solution, that will direct users to a pre-defined fallback service or feature. The automated nature of this failsafe process reduces the burden of monitoring the performance of new features on development teams, allowing them to safely release code into production without worrying about service interruptions. One stability pattern that provides this automated failover is the Circuit Breaker pattern.
2.3 Circuit Breaker
Healthbar is concerned with resiliency when deploying new features and quick recovery when services do fail, as calls to a deployed feature over a network introduce an additional point of failure. Whether the feature itself fails or the connection between services degrades, this can lead to a poor end-user experience or further outages within a distributed application.
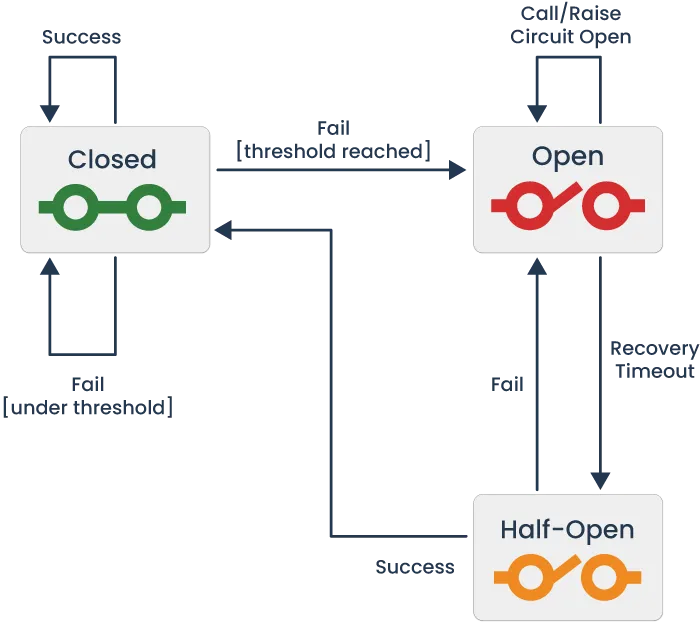
Implementation of a stability pattern can help Healthbar protect against these failures and safely recover. Stability patterns are used to promote resiliency in distributed systems [7] - the Circuit Breaker is a stability pattern popularized by Michael Nygard in his book ‘Release it,’ [8] and it is built to protect against failures as well as recover from them.
A Circuit Breaker in software is modeled after an electrical circuit breaker and is a component responsible for monitoring the flow of information from one service to another - in this case, keeping track of the failure rate of requests between two services or within a service. A Circuit Breaker controls the flow of information by changing the state of the circuit, cutting off all traffic to a service if failure rate reaches a specified threshold, and then gradually self-testing the connection to a failed service in order to re-close the circuit, allowing traffic to resume to the now-functioning service if a suitable rate of requests is successful.
2.4 Feature Flag Landscape
Healthbar developers are excited to find that there are existing feature flag solutions that meet their deployment needs. Some even come with a full set of observability, monitoring, and safety features. Because Healthbar is a small company with limited resources, the teams have to justify to management which feature flag solution to pursue.
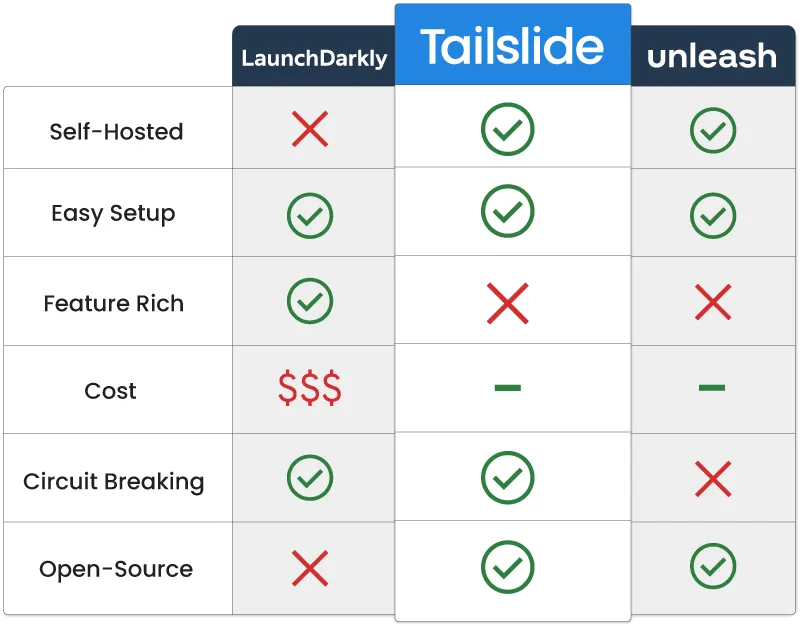
LaunchDarkly is a prominent enterprise solution. It is easy to set up and has a feature-rich platform, including integration with observability tools and circuit-breaking capabilities. However, it costs significantly more than other competing open source frameworks. Since it is hosted on LaunchDarkly platform, sensitive patient information may be stored on its cloud. Furthermore, the solution is not open source, meaning developers may not be able to configure the software to their exact needs.
Open-source frameworks, such as Unleash, typically offer either a self-hosted option or the use of their cloud platform. Although easy to set up, they do not offer the circuit-breaking functionalities Healthbar is seeking.
Finally, they found Tailslide, an open-source feature flag solution that is fully self-hosted and easy to set up. It is simple to use, and only comes with the essential feature flag elements they are looking for, such as dark launches and gradual rollouts. Most importantly, Tailslide includes an automated fault tolerant solution with built-in circuit-breaking. Healthbar decides to move forward with Tailslide as their feature flag management solution.
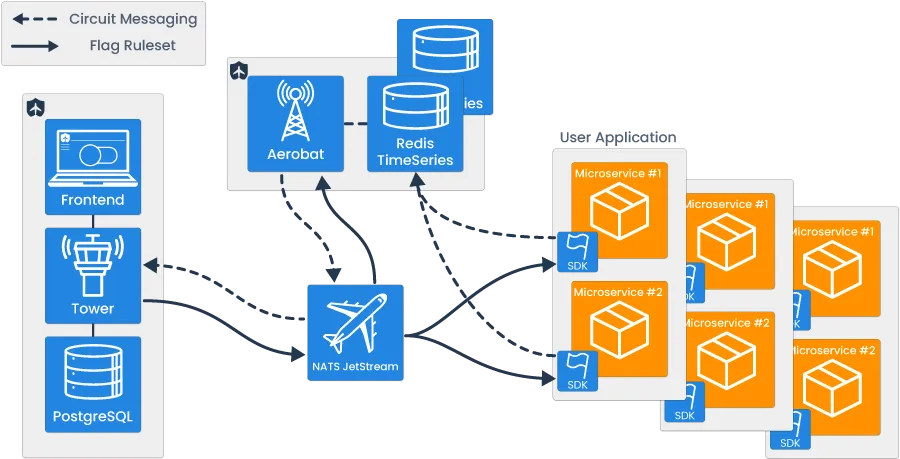
3. Tailslide Architecture
3.1 Tailslide Architecture Overview
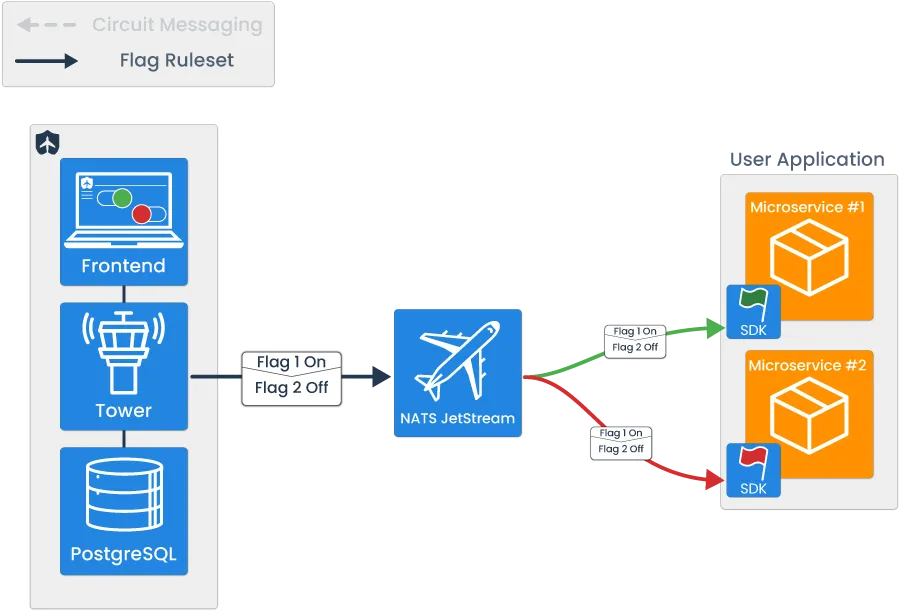
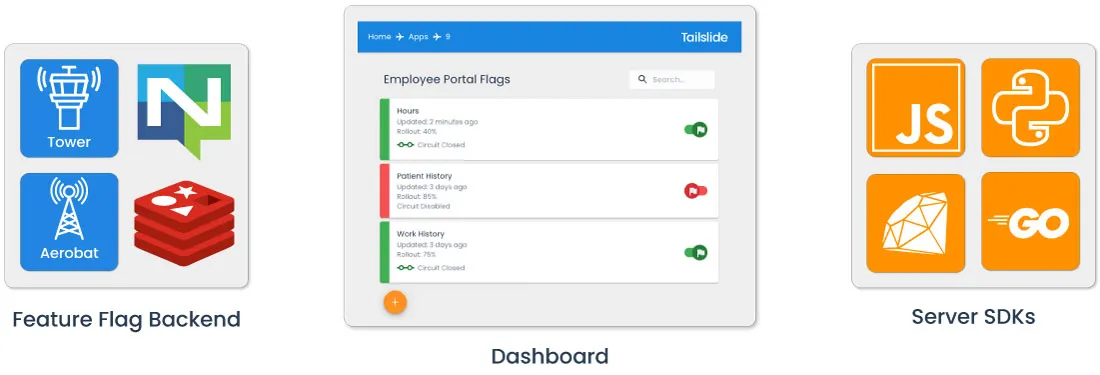
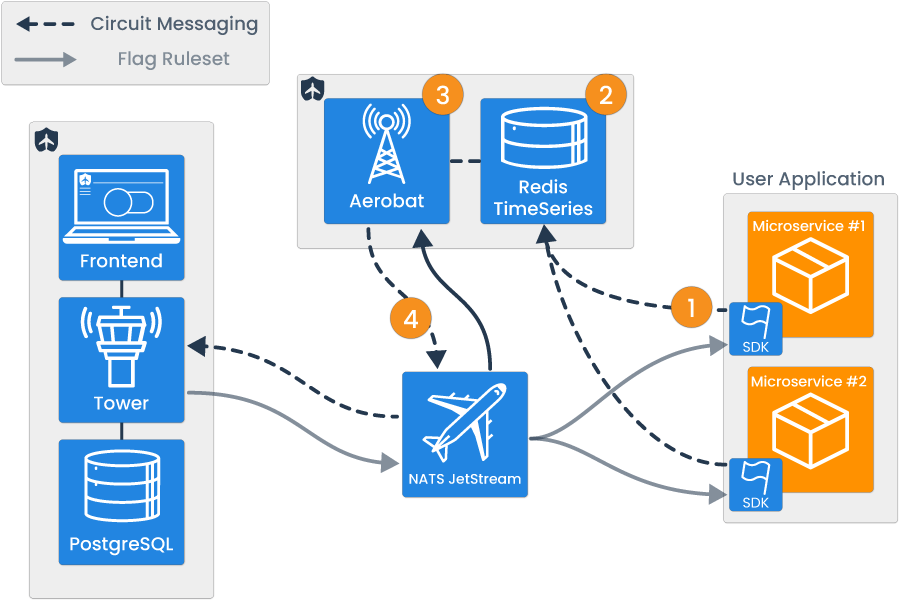
Tailslide’s architecture was built to facilitate two major uses: the feature flag ruleset data transmission and automated circuit breaking.
Note that services in orange are user-provided, and services in blue are part of Tailslide’s architecture.
The feature flag component is focused on managing CRUD operations on a per-flag basis, and propagating the feature flag ruleset data to all user microservices with software development kits (SDKs) embedded within them. By using conditional branching logic within the user microservice, the real-time transmission of feature flag ruleset data allows the developer to dynamically control the flow of application logic.
The circuit breaking component can be broken down into three major steps, which include: the emission and storage of success/failure data, the evaluation of error rate against user-configured thresholds, and the circuit state change propagation.
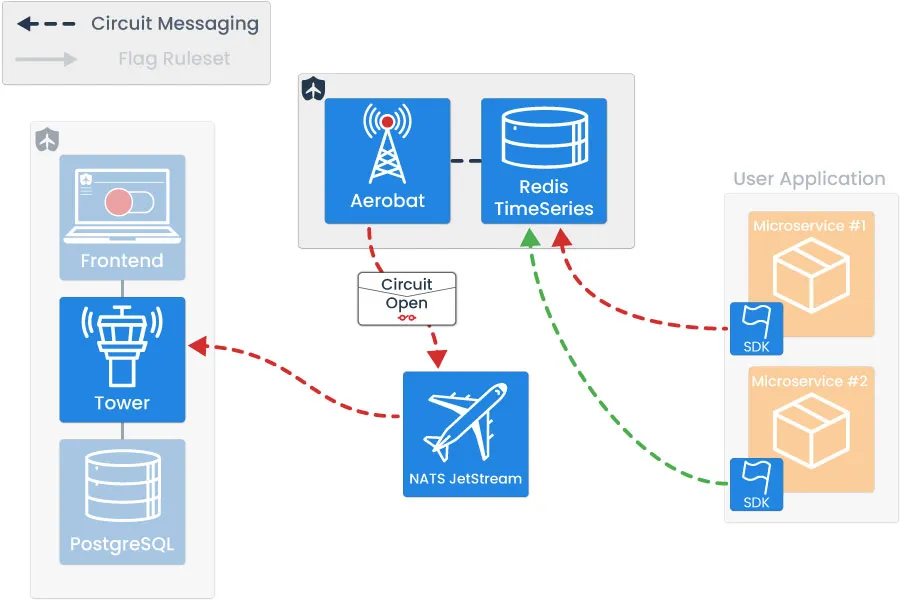
Broadly, there are four key pieces of Tailslide’s architecture. These include:
- Tower - A full-stack application that handles the CRUD functionality related to feature flag management.
- NATS JetStream - Connective technology, enabling asynchronous communication.
- Tailslide SDKs - Provides user microservices with flag state to ensure appropriate logic evaluation at runtime and emission of circuit-breaking data.
- Aerobat - A lightweight Node application responsible for all circuit-breaking logic.
We will now provide an overview of the role of each component.
3.1.1 Tower
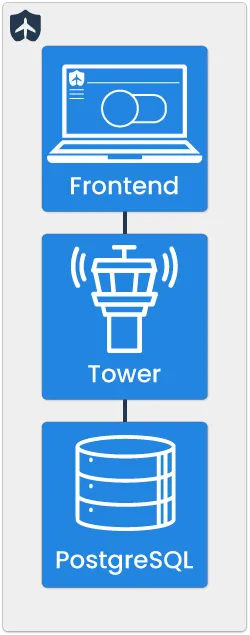
Tower is a full-stack application that handles the functionality related to feature flag management.
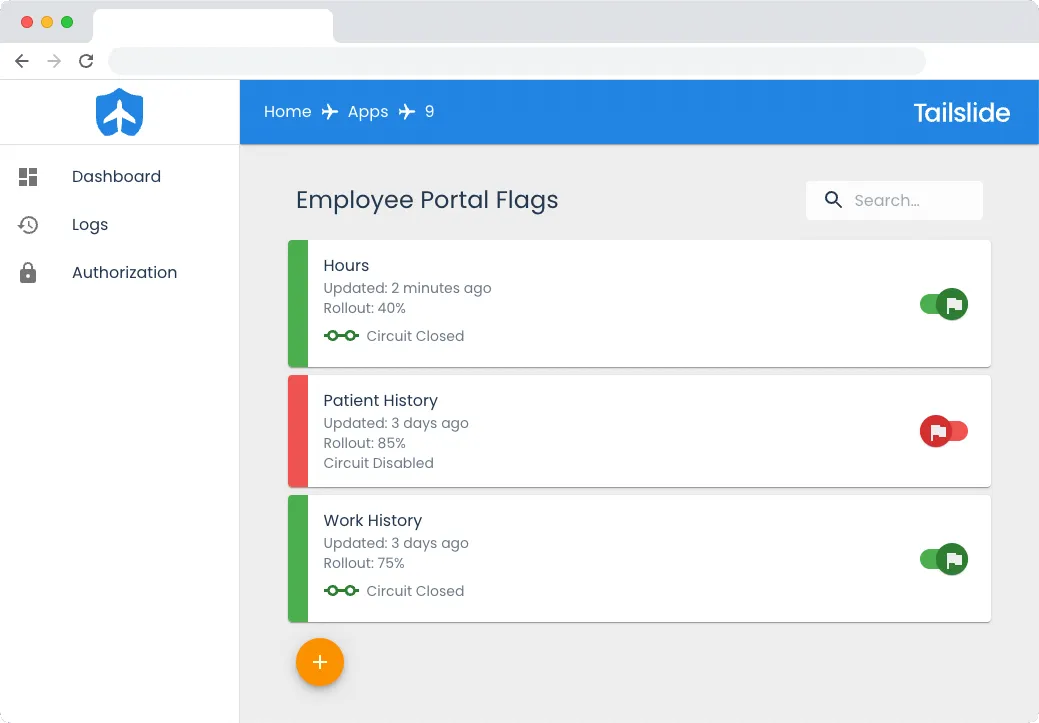
It consists of a React user interface that allows a user to perform basic CRUD functionality, such as creating an app and flag, making edits to flags, toggling a flag on and off, and viewing logs related to those flags. Each flag has a title, an optional description, an assigned rollout percentage, a field to list white-listed users, a toggle to turn the flag on/off with a single click and a variety of circuit-breaking configuration settings.
Circuit breaking settings include setting the Error Threshold, the Initial Recovery Percentage, the Recovery Increment Percentage, the Recovery Delay, the Recovery Rate, and setting the Recovery Profile as either Linear or Exponential. By default, circuit breaking is disabled, but can be enabled with a toggle switch.
Within the frontend, a user can also generate SDK Keys for use in Tailslide, view event logs of a flag’s history, and view live-circuit breaking graphs and visualizations.
Feature flag data, and any corresponding circuit breaking configuration information are stored in a PostgreSQL database.
Tower’s backend is written in Node.js and Express. Tower is configured to connect to the database, and upon any change to the feature flag data, Tower updates the database and publishes the full set of feature flag ruleset data to NATS JetStream. API endpoint documentation for Tower can be found here.
3.1.2 NATS JetStream

NATS JetStream is an open-source message streaming broker. In Tailslide, it functions as a connective technology, enabling fault-tolerant asynchronous communication. The main benefits of NATS JetStream are that it decouples publishers and subscribers, adds fault-tolerant message delivery, allows for re-sending of existing messages on the stream, and allows for authentication of publisher and subscriber applications via an SDK token. For further analysis of this tool and other options, we considered, please see Section 5.1.
NATS JetStream facilitates two types of communication in Tailslide’s architecture:
- Pub-Sub Messaging Pattern of Feature Flag Ruleset Data from Tower to User Microservices and Aerobat.
- Circuit State Change Propagation from Aerobat to Tower. (see Section 4.2.5)
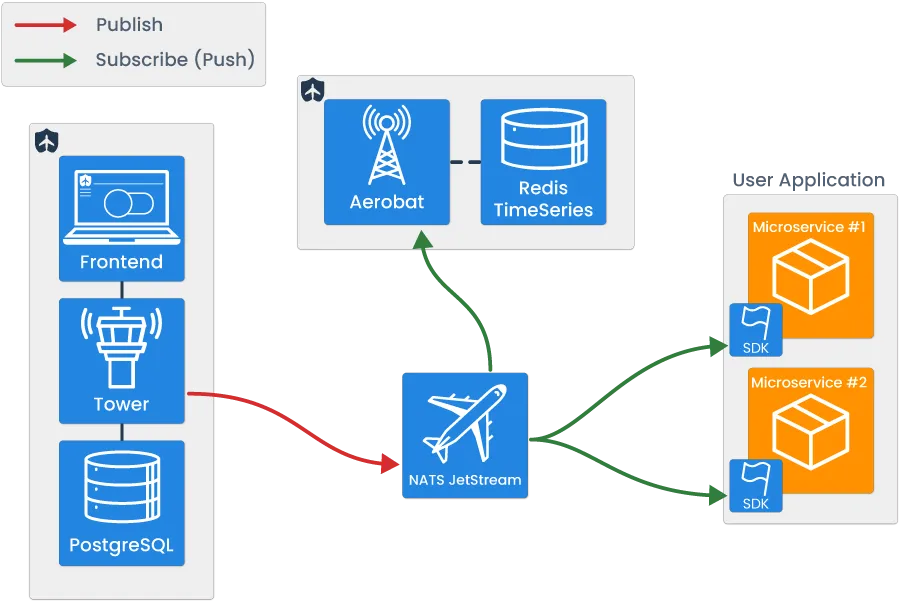
Pub-Sub Messaging Pattern - NATS JetStream supports pub-sub messaging, which is an asynchronous service-to-service communication pattern [9]. In a pub-sub messaging pattern, any message published by a publisher to a subject, is immediately received in real-time by all of the subscribers of the topic. And the default setting for the number of clients that can connect into a single NATS server and function as a publisher or subscriber is 65,536. So this provides plenty of connection bandwidth for any reasonable number of microservices [10].
For Tailslide’s architecture, any changes to the feature flag
ruleset data are published by Tower onto the
flags_ruleset subject on NATS
JetStream. The SDKs embedded within the user microservices and
Aerobat, are configured to be subscribed to any messages to the
flags_ruleset subject, ensuring that
the feature flag ruleset data is fanned out and pushed to all
subscribers.
-
Tailslide SDKs - All Tailslide SDKs require
the latest version of the feature flag ruleset data. They
require the data to ensure that the logic within user
microservices is evaluated appropriately, based on the state
(
true/false) of the flags at runtime. - Aerobat - Aerobat requires the latest version of the feature flag ruleset data, as the data also contains each flag’s circuit-breaking settings, including essential information such as the Error Threshold for each circuit. Current rules are stored as an internal state and are updated when a new ruleset is received. Based on this data, Aerobat knows which flags have active circuits that need to be queried and assessed against the configured Error Threshold.
Horizontal Scaling - Tailslide was built to handle horizontally scaled instances of user microservices, and it does so via both message replay and the pub-sub pattern. Message Replay allows a message broker to resend an existing message on the stream, to a subscriber.
When a new user microservice comes online, the subscriber SDKs
are configured to poll the NATS JetStream
flag_ruleset subject for the last
sent message, which represents the latest feature flag ruleset
data. Any additional updates to the feature flag ruleset data
are received by the SDKs via the Pub-Sub messaging pattern.
3.2.3 Tailslide SDK
Tailslide SDKs are libraries which can be embedded into the code of backend user microservice applications, which allow for the access of feature flag ruleset data and the emission of success/failure data for circuit-breaking capabilities. Please see Section 4.2.2 for details on the success/failure data emission.
Tailslide provides server-side SDKs written in four languages, including JavaScript, Ruby, Python, and Golang.
To use the SDK, a user will first install the library and then
create an instance of a new
FlagManager via a configuration
object. The configuration object includes fields such as the IP
address of the NATS JetStream, the
appId, the
sdkKey, and a
userContext field, which is a value
that uniquely identifies an end user (i.e. session cookies
identifier or a username).
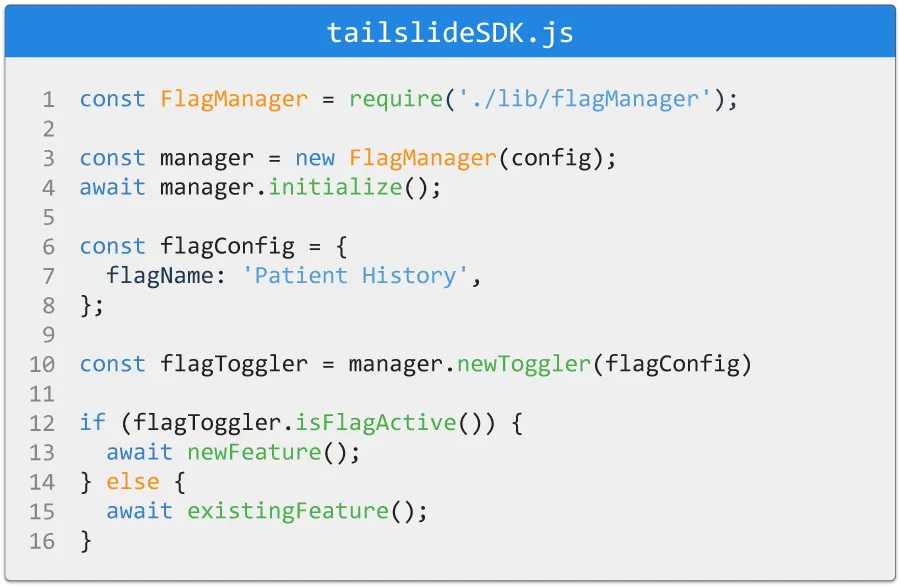
The initialize method must then be
called on the FlagManager. This
method initiates a subscriber connection to the NATS JetStream
flags_ruleset topic and retrieves
the latest feature flag ruleset data.
The newToggler method on the
FlagManager can then be invoked. This creates a new toggler
object required for each feature. These toggler objects contain
the feature flag ruleset data for the flag with the
corresponding flagName. The toggler
objects define methods such as
isFlagActive. This method returns a
boolean that can be used to determine which branch should be
evaluated in conditional logic of user microservice application
code, thus effectively allowing for control of feature release
at runtime.
The isFlagActive function is
evaluated based on the flag status, white-listed users, and
rollout percentage.
The userContext information can be
updated within the user microservice application code by the
user. This field is crucial in order to ensure that both
white-listed users and percentage rollout fields are evaluated
appropriately. The userContext field
can be modified with the
setUserContext method. The
setUserContext method will update
each existing instance of the toggler to incorporate the new
userContext.
Please see Section 4.1.1 and Section 4.1.2 for further detail on white-listed users and rollout percentage implementations.
3.2.4 Aerobat
Aerobat is a lightweight Node application and the central point of Tailslide’s Circuit Breaking capabilities, responsible for all Circuit Breaking logic.
Aerobat is configured to spin up a process for each application
with active circuits. Aerobat determines an active circuit based
on the feature flag ruleset data, which it receives as it is
subscribed to the
flags_ruleset subject on NATS
JetStream.
Aerobat connects directly to Redis and is primarily responsible for querying the cache for each live circuit within an application on a periodic interval to evaluate current error rates against user-configured error thresholds. This allows Aerobat to assess the health of circuits and update circuit states accordingly. Any changes to circuit state result in Aerobat publishing a message onto a specific circuit state change subject on NATS JetStream, to which Tower is subscribed.
4. Technical Deep Dive
4.1 Feature Flags
Feature Flags enable the decoupling of deployment from feature release. They do so by having feature releases occur within the application code at runtime. To use Tailslide, first create flags in the frontend. Within the Tailslide SDKs, create new toggler objects. These toggler objects can obtain the flag ruleset data for particular flags. The Tower backend server transfers flag ruleset data to the Tailslide SDKs via NATS JetStream. This ensures that at runtime, the appropriate flag ruleset data is used to evaluate the branching logic with the application code. Tailslide also provides additional options to further customize what flag ruleset data a user will be presented, including white-listed users and a gradual percentage rollout.
4.1.1 White-Listed Users

White-Listed Users can be added to a flag within the frontend
UI. Developers can use this property to ensure that for these
particular users, the flag status will always evaluate to
true, if the
isActive property on a flag is also
set to true. Recall - instantiating
toggler objects requires a
userContext property which uniquely
identifies a user.
If a userContext is included within
the list of white-listed users of a particular flag, then that
specific white-listed user will be shown the new feature. This
feature of Tailslide allows developers to easily test their new
features in production without affecting the regular user
experience.
4.1.2 Gradual Percentage Rollout
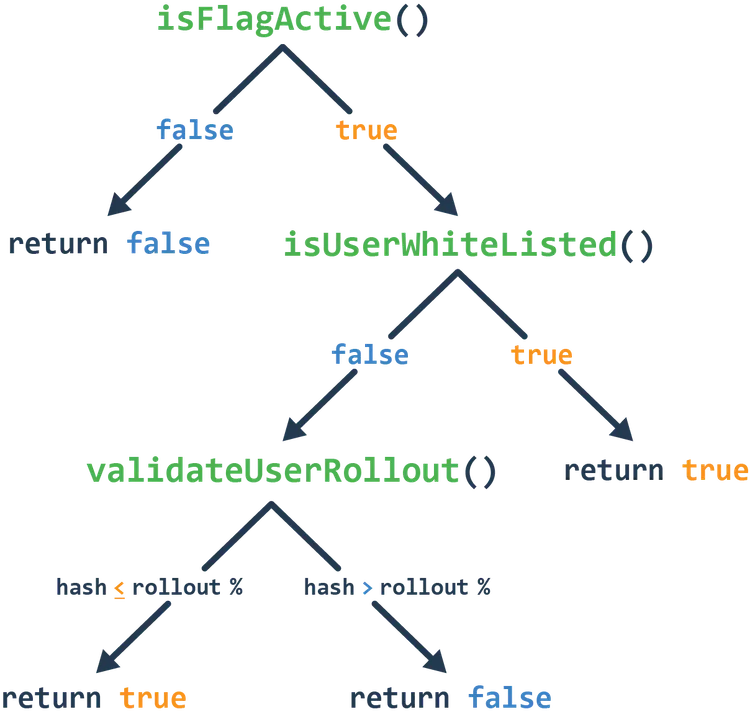
Tailslide also allows for the gradual rollout of specific features to a subset of the user base. This is done via hashing.
Recall that whenever a
toggler object is instantiated
within the application code of the user microservice, the
userContext is also passed in, which
represents the unique identifier for a user. That
userContext is hashed to generate a
number between 1 and 100. If that hashed number turns out to be
greater than the rollout percentage, the flag will evaluate as
false, and if the hashed number
turns out to be less than or equal to the rollout percentage,
the flag will evaluate to true.
Note: The same hashed value will be used to evaluate all flags in a particular app for the same user.
Because effective hashing functions uniformly distribute the data across the entire set of possible hash values, this process ensures that the distribution is in line with the percentage rollout figure set.
Note that the gradual rollout validation occurs after the white-listed user check - see the logic flow evaluation tree.
4.2 Circuit Breaking
4.2.1 Circuit Breaking in Tailslide
Tailslide takes a unique approach to implementing the circuit breaking pattern within its architecture to serve the deployment of features in a microservice architecture as well as integration with a feature flag management system.
The circuit breaking architecture integrates with feature flags by observing the health of connections to newly deployed services and automatically cutting off these connections when failure occurs. These connections are disabled by automatically toggling a flag off, allowing the application to fall back to the pre-existing code or alternative feature, and preventing any wider disruption of service.
Connections to services can then be gradually reestablished when an appropriate amount of time has elapsed through an automated recovery process which sends a reduced amount of traffic to the deployed feature. If recovery is successful, the breaker will be reset, and will return to a fully closed state (the flag will be automatically toggled on).
Zooming in on the implementation of Circuit Breaking itself, the flow of information can be broken down into four steps:
- Success/Failure Emission
- Timeseries Data Storage
- Error Rate and Circuit State Evaluation
- Circuit State Change Propagation
4.2.2 Success/Failure Emission
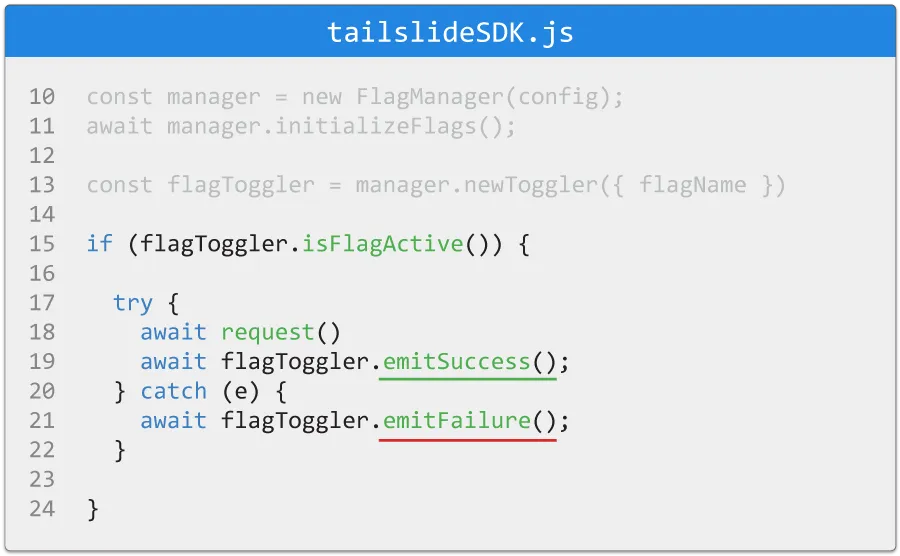
The first stage of Circuit Breaking is the emission of success
and failure data. This takes place within the user
microservices themselves by monitoring the success of calls to a
deployed feature using the Tailslide SDK. By instantiating a
toggler object, a developer exposes the
emitSuccess() and
emitFailure() methods for a specific
flag.
These methods are used to signal a successful or failed operation as related to the deployed feature. As opposed to a traditional circuit breaker function wrapper, these methods are exposed to allow the developer to explicitly call as they see fit, based on their own success/failure conditions. A single success or failure signal is emitted for each invocation.
4.2.3 Timeseries Data Storage
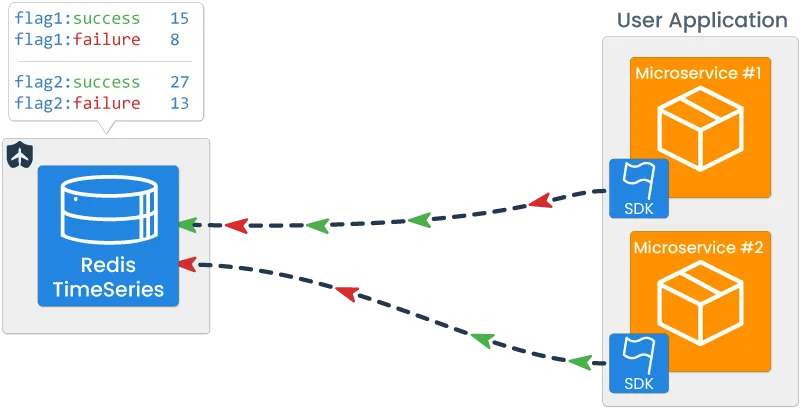
Redis Timeseries is a timeseries module built on top of a Redis
cache. It is optimized for high throughput and the
storage/querying of data with an aspect of time [11]. The
Tailslide SDK within each user microservice is configured to
connect directly to the cache for writing every time the emit
methods are invoked. Each data point written to the cache is
stored under a key defined by
flagID:success/failure.
Along with Flag ID, success/failure status and App ID metadata, each data point receives a timestamp correlating with the time at which the success or failure took place. This is an important aspect of Tailslide’s Circuit Breaking capabilities, and allows queries within a specified time window. This is the key to evaluating real-time error rates for each circuit and also enables Tailslide to provide graph visualizations of circuit health.
Redis Timeseries also defines a time-to-live (TTL) for all data. Tailslide configures its cache with a 1 hour TTL policy, as this is the maximum time data is needed. This data is ephemeral in nature, and clearing out stale data allows Tailslide to minimize memory usage.
Horizontal Scaling
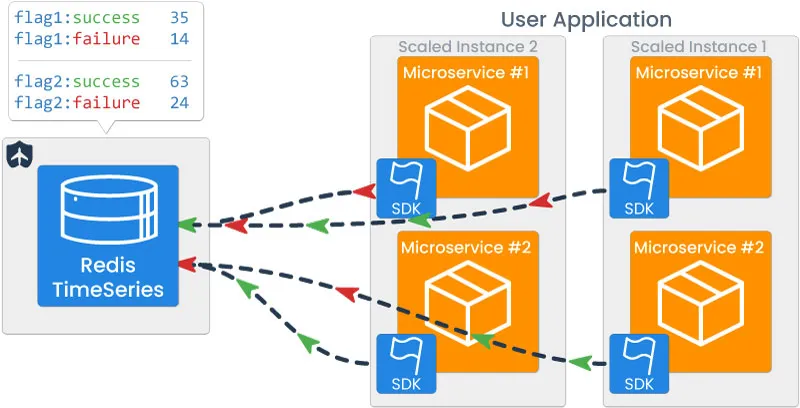
An important distinction between some pre-existing circuit breaking libraries and Tailslide is that Tailslide is built to handle scaled user microservices and thus evaluates circuits in-aggregate. From an architectural standpoint, this means that all instances of a feature deployed via a feature flag, even if scaled horizontally many times, must be analyzed as a single circuit.
To handle this scaling, data for each specific flag is stored under a single key, with no knowledge of which instance of a user microservice wrote the data to the data store. By identifying data only by flag ID, Tailslide can take a holistic approach to evaluate circuit health, and avoids the case in which a circuit for the same feature is in different states across multiple scaled instances. This ensures a consistent application state for the entire user-base.
4.2.4 Error Rate and Circuit State Evaluation
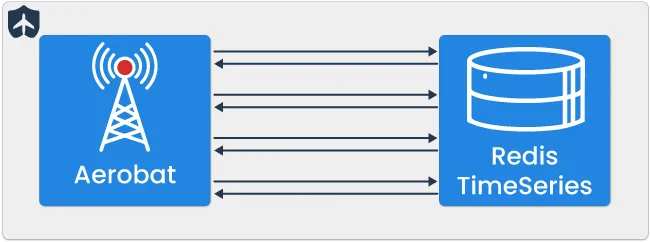
Recall that Aerobat is the central point of Tailslide’s Circuit Breaking capabilities. Aerobat connects directly to Redis and queries the cache for each live circuit within an application to evaluate current error rates against user-configured error thresholds, allowing Aerobat to assess the health of circuits and update circuit states accordingly. Aerobat determines whether a circuit should be tripped open by monitoring a circuit’s error rate through polling Redis at a developer-defined interval. This polling relationship ensures Aerobat is constantly evaluating the circuit based on current success and failure counts.
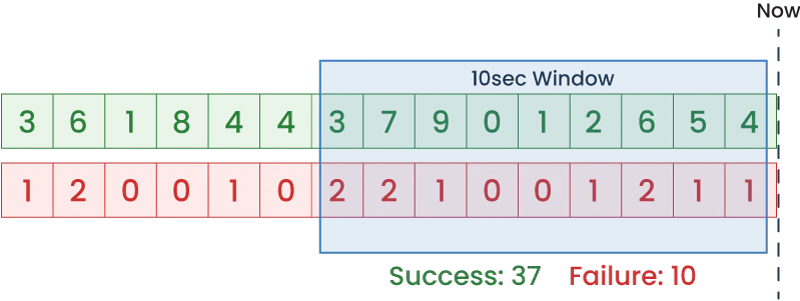
Aerobat calculates error rate percentage by querying the sum of success, and failure counts over a developer-defined window of time. Due to the data being stored in a timeseries structure, Tailslide can fetch sum values with a single query by providing Redis a window start and window end timestamp, representing the current time minus the window size and the current time itself. Querying over a window of time allows Aerobat to protect against sudden spikes or lulls in data and effectively creates a sliding window for evaluating error rates. Engineers can configure both the query window and polling rate to better fit their new feature’s needs based on the expected traffic and risk tolerance.
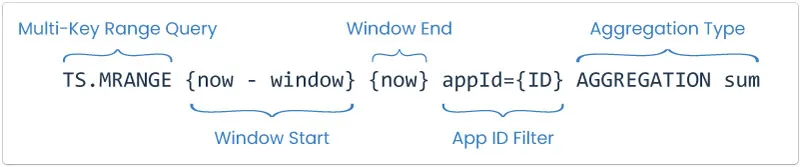
Aerobat can efficiently query Redis for all active flag data within an application by making a multi-key query, leveraging Redis Timeseries metadata label tags. All flag keys have an associated app ID that can be used to make this query, returning a summed count of successes and failures in the window range.
With each query, Aerobat calculates the error rate percentage and then makes a simple check for the error rate percentage surpassing the user-defined error threshold percentage. If this check evaluates true, the circuit is tripped open.
4.2.5 Circuit State Change Propagation
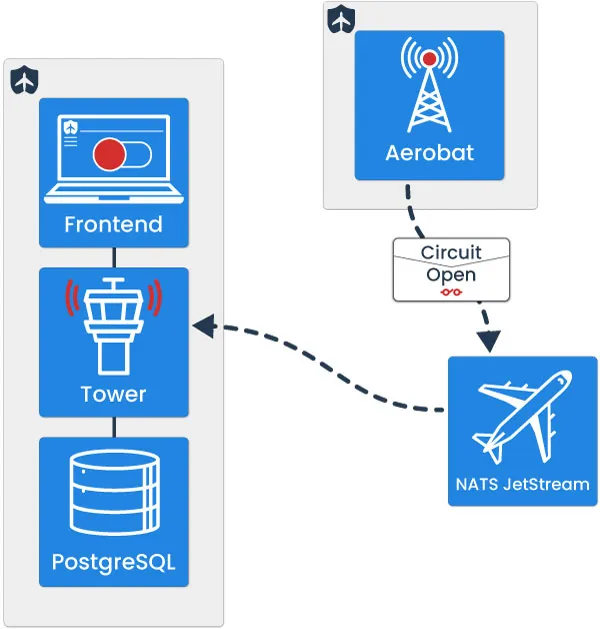
Aerobat is responsible not only for evaluating a circuit’s state change, but also for notifying Tower of the change. Tower can then persist this change of circuit state in PostgreSQL and propagate the update back out to all SDKs.
Aerobat publishes messages via a JetStream subject dedicated to circuit state changes. Tower is subscribed to this subject and is configured to immediately update a flag’s state to off if a circuit is tripped open, as well as updating internal circuit properties for display purposes. Tower will also store an event log related to any change in state, which can be viewed on the Tailslide dashboard.
Any change in feature flag ruleset data or configuration is immediately published by Tower to NATS JetStream, and propagated out to all connected SDK instances, allowing circuit state changes to quickly take effect within a user application. This effectively completes the cycle of information within Tailslide - with Tower publishing flag ruleset data, Aerobat monitoring the health of connections created by these flags, and automatically shutting off flags according to circuit breaking configuration.
4.3 Automated Recovery

While Tailslide’s default behavior of tripping open a circuit protects against a failing feature, it still requires an engineer to respond to the failure to assess the issue and ensure the service is recovered before turning the flag back on and closing the circuit. This Time to Recovery can increase if an engineer is unavailable, especially during weekends or nights, leading to additional downtime for a feature and a degraded user experience. An increased burden on engineering staff also takes away valuable time that could be used on development instead of the maintenance and monitoring of deployed features.
Tailslide has developed a solution to lessen the support burden and decrease MTTR with an automated recovery system that follows the principles of a Circuit Breaker half-open state. As defined by Michael Nygard:
"When the circuit is “open,” calls to the circuit breaker fail immediately, without any attempt to execute the real operation. After a suitable amount of time, the circuit breaker decides that the operation has a chance of succeeding, so it goes into the “half-open” state. [12]."
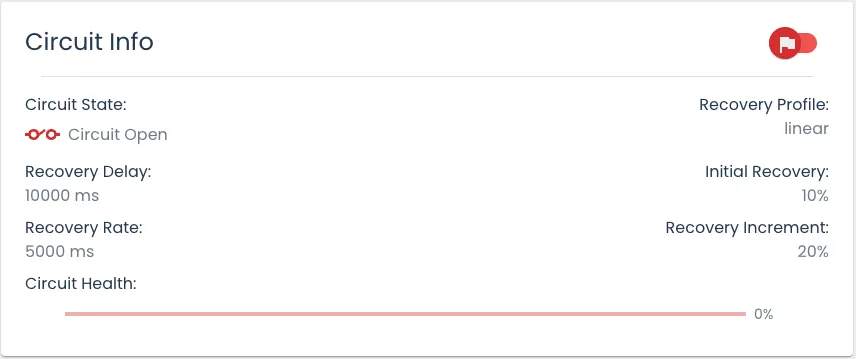
In Tailslide, this “suitable amount of time” is a configurable
Recovery Delay Time, during which the circuit will remain in an
Open state and the flag state evaluates as
false.
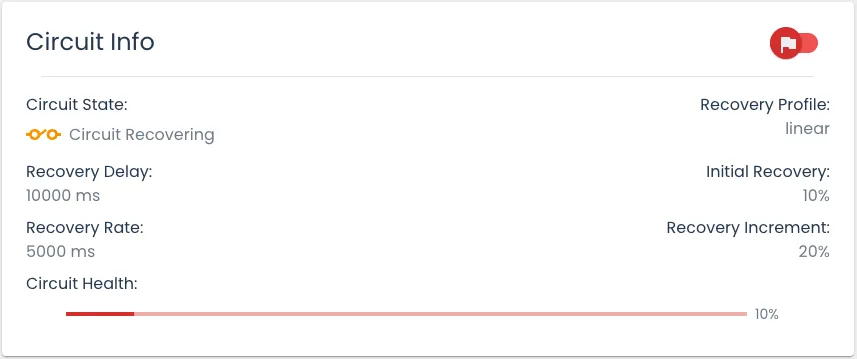
After the recovery delay has elapsed, the circuit enters a Recovery state, acting as a half-open circuit. During this phase, a decreased amount of users are exposed to the new feature, as defined by the ‘Initial Recovery’ percentage.
This change of state is handled by Aerobat, which is aware of all recovery configurations via the feature flag ruleset data. Aerobat is responsible for tracking the recovery delay and, once the time has elapsed, updating the circuit’s state to in-recovery. With each state change, Aerobat publishes a new message back to Tower, which is propagated to all SDK instances to adjust the percentage of users exposed to the feature.

While a circuit is in the Recovery state, it
will gradually increase the number of users exposed to the
feature. This percentage is increased by a ‘Recovery Increment’
percentage which is incremented at a set interval defined by the
‘Recovery Rate.’ A user has granular control over each of these
settings and can even define recovery shape by choosing either
linear or
exponential.

During recovery, Aerobat continues to monitor a circuit’s error rate against the error threshold. If at any point the threshold is surpassed, the circuit will return to an open state, and the recovery process will restart. If the circuit health reaches 100% without tripping open, the circuit will be considered fully recovered, and will return to a closed state, exposing the feature to all users defined by the rollout percentage.
4.3.1 Circuit Monitoring
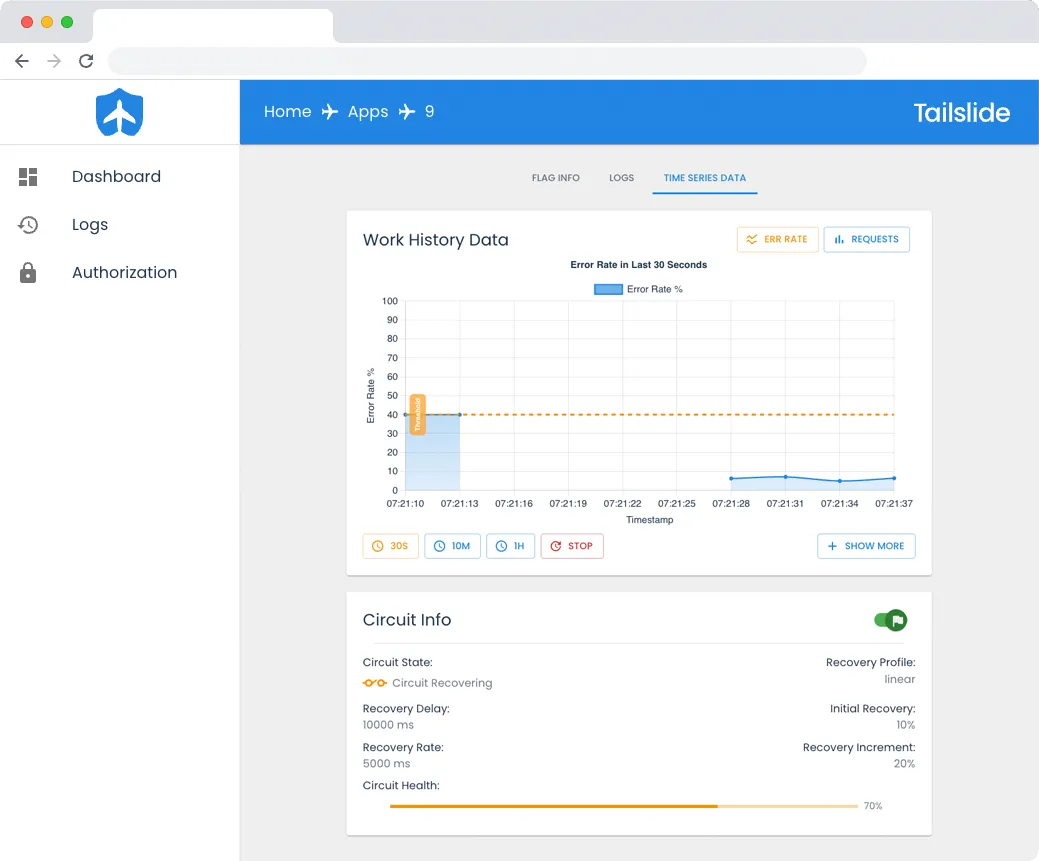
Even with automated recovery enabled, developers should be aware of the health of circuits and any changes to their state. Repeatedly tripped circuits can point to a need for retuning error thresholds, or a larger issue within a user application or feature. Tailslide has implemented two means of monitoring circuits in real-time.
The first is the ‘Circuit Health’ tab available for each flag on the Tailslide frontend. This page displays graph views of error rate along with error threshold, as well as a bar graph displaying success and failure counts. Various time windows are available for analysis, from the past 30 seconds to an hour. The graphs are implemented with Chart.js and receive real-time updates by polling a timeseries endpoint in the Express backend, which queries the Redis Timeseries cache according to the selected window.
This graph visualization is paired with a ‘Circuit Info’ card that gives a live view of a circuit’s current state. Real-time updates are implemented by creating a websocket connection between the React app and the Express backend using NATS WebSocket, which pushes updates when circuit state changes. The React app updates the display as a circuit opens, recovers and closes, along with the current Circuit Health percentage.
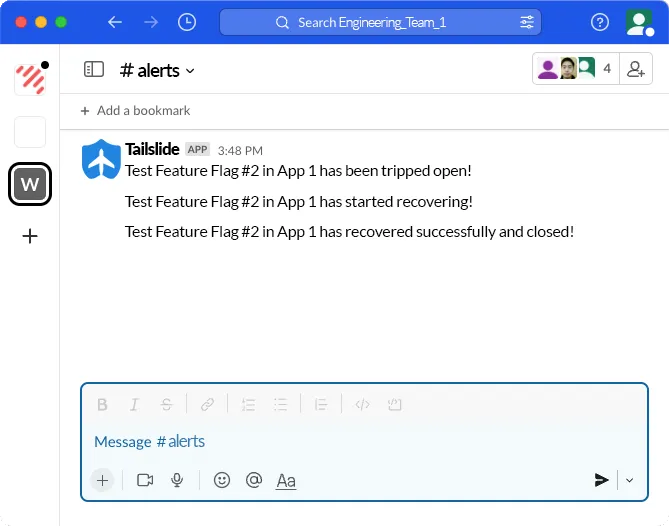
Tailslide also allows developers to configure Slack channel alerts for any changes in a circuit’s state. A developer can input a Slack webhook URL on the Tailslide dashboard when creating or editing a flag. The Tower express app will then send a POST request with details of the flag and its updated state to all configured URLs anytime there is a change, providing the flag name and the event description, giving developers peace of mind knowing they will be immediately alerted to changes in state.
4.4 Using Tailslide
4.4.1 Deploying Tailslide
Tailslide is a self-hosted, open-source feature flag framework. Since Tailslide is not a managed solution, all data is stored on the user's own infrastructure and is not shared with any external parties.
Tailslide provides a simple out-of-the-box deployment strategy, which will spin up all components of Tailslide on a single server within a Docker Network.
To deploy Tailslide with Docker, a user needs to first clone the
docker branch from GitHub, then ensure the appropriate
configuration files are present, and pass in an
SDK_KEY argument along with the
docker-compose up command. SDK Keys
can be generated from the frontend UI.
Depending on a user's needs, Tailslide also offers individual components such as Aerobat and Tower, as separate repositories on Github. These can each be hosted on individual machines or with any hosting service. This provides the flexibility to scale and use different components as needed. Providing users with the ability to deploy individual components allows a user to add to their implementation of Tailslide, making it more robust.
5. Engineering Decisions and Tradeoffs
5.1 Service-to-Service Communication
One of the key engineering decisions made was how we were going to reliably facilitate service-to-service communication. In Tailslide, service-to-service communication occurs when Tower communicates flag information to both Aerobat and the user microservices, and when Aerobat communicates circuit change state information back to Tower.
Due to the nature of our application, this communication needed to happen in real-time. For example - if a flag is manually toggled off, this information would need to be transmitted out to all consumers simultaneously. The communication also needed to be fault tolerant. Some guarantee of delivery is required to ensure that the message is eventually received by the subscriber, and not lost during transmission even if a subscriber is temporarily unavailable. In addition, when a new user microservice comes online, it would need to gain access to the latest flag ruleset data. Lastly, it needed to be secure and provide authentication. This ensures that only authorized applications receive the flag ruleset data.
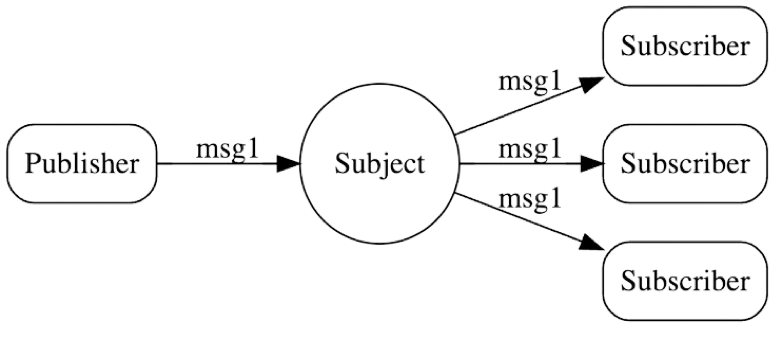
The solution we used to address these problems was NATS JetStream. NATS JetStream is a lightweight, open-source message streaming broker.
NATS JetStream supports the Pub-Sub Communication Pattern, which is a form of asynchronous service-to-service communication where any message published to a subject by a publisher is immediately received in real-time by all subscribers of the subject. This communication pattern allows all changes to the flag ruleset data to instantly be fanned out to both Aerobat and all user microservices with the Tailslide SDK.
NATS JetStream also provides guaranteed-at-least-once delivery, which ensures that for each message handled by the message broker at least one delivery will be successful, though there may be more than one attempt made to deliver it. Due to this property, we created Tailslide with idempotence built in. See Section 5.4.1 on idempotence.
In addition, NATS JetStream supports message replay, which allows message brokers to resend messages to new or existing subscribers, regardless of when a message was first received by the message broker. Because the entire flag ruleset for an app is sent with each transmission, a new user microservice can get access to the latest flag ruleset data by resending the last message on the stream.
Lastly, NATS JetStream allows for authentication via a token which secures our application against unauthorized access.
Other options considered included creating our own custom-built solution and utilizing server-sent events to fan information out to consumers. Although feasible, this option requires all features being built from scratch and could result in an increase in engineering hours. We also considered RabbitMQ, an open-source message broker, however this technology did not support message replay. Kafka was also considered, which is an event stream-processing platform. Although it has all the capabilities we desired, it is intended to be used for very high-volume throughput event-driven architectures and is a complex and feature-rich tool. Since we don’t anticipate flag ruleset data being changed on a very frequent basis and we were looking for a more lightweight tool, we opted against using Kafka.

5.2 Circuit Breaking
Another major engineering decision we made was around how we were going to architect our circuit-breaking functionality. This was broken into three main decisions:
- Emission of Data
- Storage of Data
- Evaluation and Communication of Data
5.2.1 Emitting data
We need to keep track of whether the circuit of a feature flag is operating as expected or failing. To do so, the user’s application needs to be able to share data about successful or failed operations related to the feature deployed behind a flag. We can then query a record of this data to assess the health of a circuit for a particular flag.
We decided to emit telemetry data based on user-defined success and failure events as this approach provides users with flexibility, allowing them to decide for themselves what their specific success/failure criteria would be.
We considered emitting telemetry data using existing tools, such as OpenTelemetry. This data would be in a standardized format, and could consist of logs and metrics. However, this approach would involve tracking additional data not needed for Tailslide. Because we were looking for a lightweight and simple solution, we opted not to pursue this option as it resulted in increased complexity.
5.2.2 Storing data
Our next challenge was to determine where the SDK should send event data for storage. Our data store needs to support a high-volume write throughput, as every connected SDK will write to the data store when they invoke a success or failure event. In addition, the data being stored is ephemeral in nature and is very simple - it would consist of an identifier for the flag, a timestamp that indicated when the write occurred, and if it was a failure or success event.
We decided to use Redis Timeseries, which is an implementation of Redis that added a Timeseries data structure to Redis. Redis is an open-source, lightweight in-memory data store, which was simple to use, simple to deploy, and allowed for high volume throughput and performant read and write capabilities. Using Redis Timeseries allowed us to group the timeseries data into buckets for assessment by Aerobat. It also allowed us to set a TTL on that data, so that stale data could be cleared out periodically. This is an important feature due to the high volume of data that needs to be ingested. Time-bucketed data can then be sent to the front-end for graphing and visualization purposes. For these reasons, we decided to pursue the usage of Redis Timeseries as our data store.
We also considered using NATS JetStream. This solution would leverage our existing infrastructure and involves having the SDKs publish directly to a success or failure message log topic within NATS JetStream. The message log would then be queried periodically. Although feasible, we opted not to pursue this option as consistent time-bucketed querying of persisted messages in a message broker is a more complex process that was not natively supported by NATS JetStream.
We also considered using a timeseries database, such as InfluxDB. However due to the simplicity of our data and our specific use case, we chose not to pursue this alternative.
5.2.3 Data Evaluation and Communication
Once the success/failure telemetry data has been stored, it must be queried at a periodic interval to assess if a circuit for a flag has been tripped. If a circuit has tripped open, this information needs to be communicated back to Tower to update the database to reflect the correct flag state, so that the latest flag ruleset data can then be published and fanned out to all subscribers.
To facilitate this communication, we engineered Aerobat to publish circuit state change events to NATS JetStream, and configured Tower to subscribe to those corresponding subjects. This approach provides reliability, as NATS guarantees at-least-once-delivery, which ensures that all circuit state change events published from Aerobat will be received by Tower at least once.
The other option considered was to set up an API endpoint on Tower, and have Aerobat communicate directly with Tower using HTTP Requests sent over the network. Although this was a feasible approach, it would not be fault tolerant because it could be susceptible to dropped messages due to network unreliability.
5.3 Self-hosted vs. Hosted
Another question we needed to answer was how Tailslide would be deployed. There were two options: hosted vs. self-hosted.
In a hosted solution, we would host Tailslide on private cloud infrastructure and offer access to Tailslide as a service to users.
In a self-hosted solution, we would require the user to host Tailslide on their own infrastructure.
We decided to provide Tailslide as a self-hosted application due to the following reasons:
- Open Source and Component Flexibility - By allowing user organizations to self-host Tailslide, different components of the architecture could be scaled up or scaled down as needed, based on load. For example - if a user organization was using the circuit-breaking functionality intensely, an additional Redis Timeseries component could be added to the infrastructure, which would allow for increased read and write volume. In addition, since Tailslide is an open-source and self-hosted application, user organizations can easily modify Tailslide as needed to suit their own unique needs and requirements.
- Infrastructure Deployment Flexibility - By allowing users to deploy Tailslide on whatever infrastructure they choose, it gives them the freedom to deploy on a variety of platforms - such as an AWS EC2 instance, a DigitalOcean Droplet, or even their own on-premise server.
- Risk Management - By allowing users to self-host Tailslide, it reduces the security risks that a user organization may have with sending confidential flag data to a third-party organization. By offering a self-hosted solution, users retain sole control of their own flag data and do not need to rely on the security measures in place of an external organization.
5.4 Server-Side SDKs
When flag data is changed, a question arises around which type of data should be distributed. The key question being:
- Should we send only the single flag ruleset of the changed flag, or
- Should we send the entire flag ruleset for an application?
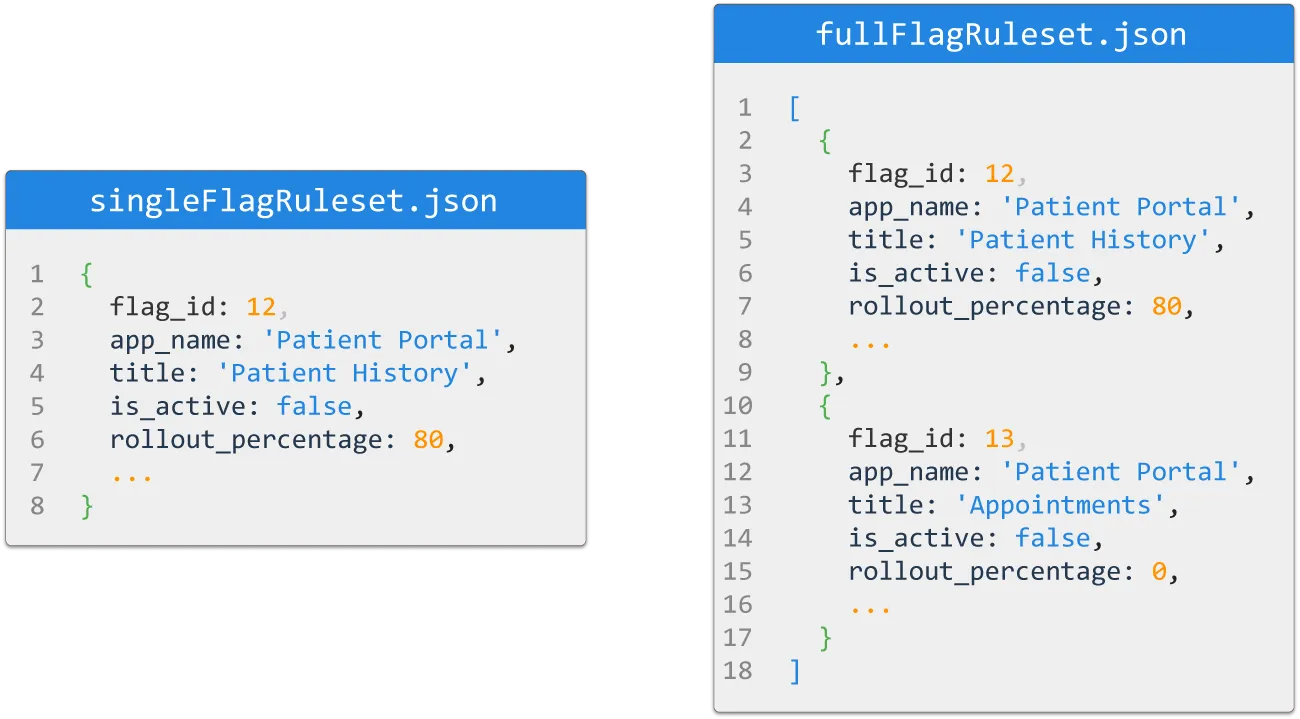
Sending the entire flag ruleset is common for server-side SDKs, whereas sending the specific single modified flag ruleset data is more commonly seen in client-side SDKs. [13]
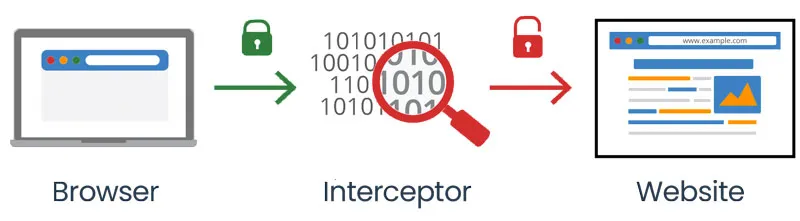
This is because client-side SDKs are embedded in applications that are distributed to users, such as a React or a mobile application. It is less safe to store sensitive information on client-facing applications, as your users can then intercept and inspect the network traffic to see what feature flags you have created and view what your current targeting rules are.
To reduce the risk of unauthorized access to flag data, client-side SDKs often only provides the client with access to single flag data and require an authentication key for access.
Contrast this with server-side SDKs - these SDKs are intended to be used in applications that run on the backend. Therefore, these environments are considered to be safer environments, where the risk of network traffic interception and inspection is decreased.
- Server-Side SDKs - Because Tailslide was built to improve the deployment process for testing new backend functionality, it is intended only to be used in this context, which is considered a safer environment. Therefore, the transmission of the entire flag ruleset data for an app is deemed to be appropriate and in-line with industry practice around how server-side SDKs are often implemented. For additional security - applications still need to provide an SDK Key for authentication before being granted access to the flag ruleset data.
- Simplicity - In addition, this approach is simpler to implement as every time a flag is modified, the entire flag ruleset for an application is published.
- Anticipated Flag Ruleset Data - Lastly, we would anticipate that the flag ruleset data is not prohibitively large, given our target user. Therefore the transmission of the entire flag ruleset would not result in a significantly longer transfer period relative to a single-flag ruleset.
5.4.1 Idempotence

What is an Idempotent Operation? An idempotent operation is one where a request can be retransmitted or retried with no additional side effects, a property that is beneficial in distributed systems. [14]
At-Least-Once Delivery and Idempotence - One of the guarantees provided by NATS JetStream is at least once delivery, meaning that the identical feature flag ruleset data could be sent twice by the message broker. Because the entire flag ruleset data is sent every time, even if the identical flag ruleset is transmitted more than once - the Tailslide SDK embedded within the user microservice would respond in exactly the same way, evaluating the logic within the backend application as appropriate.
6. Future Work
Future Work we are considering includes:
- User Authentication to Front-End UI - Having users authenticate before being granted access to the Front-End UI. This would allow for the ability to see the change history, such as who toggled a flag on/off or who edited the circuit breaking options for an existing flag.
- Additional SDKs (C#, Java) - We are looking toward adding SDKs in additional languages to support our users. Currently, the client library SDKs we support include Python, Golang, JavaScript, and Ruby. In the future, we would like to add additional popular back-end languages such as C# and Java.
- Circuit Breaking using Additional Criteria - We are also looking to add the ability for users to implement circuit breaking based on other trigger criteria, such as user-defined HTTP response codes and user-configured response times thresholds, specifically when the circuit breaker is used for synchronous service-to-service communication.
7. References
- Launch Darkly, "Deployment and release strategies," https://docs.launchdarkly.com/guides/infrastructure/deployment-strategies.
- Kostis Kapelonis, "The Pain of Infrequent Deployments, Release Trains and Lengthy Sprints," https://codefresh.io/blog/infrequent-deployments-release-trains-and-lengthy-sprints/.
- LeanIX, "The Definitive Guide to DORA Metrics," https://www.leanix.net/en/wiki/vsm/dora-metrics.
- Atlassian, "MTBF, MTTR, MTTA, and MTTF," https://www.atlassian.com/incident-management/kpis/common-metrics
- Tomas Fernandez, "What is Canary Deployment?," https://semaphoreci.com/blog/what-is-canary-deployment.
- Pete Hodgson, "Feature Toggles (aka Feature Flags)," https://martinfowler.com/articles/feature-toggles.html
- Gregor Roth, "Stability patterns applied in a RESTful architecture," https://www.infoworld.com/article/2824163/stability-patterns-applied-in-a-restful-architecture.html.
- Martin Fowler, "CircuitBreaker," https://martinfowler.com/bliki/CircuitBreaker.html.
- AWS, "Pub/Sub Messaging," https://aws.amazon.com/pub-sub-messaging/.
- NATS, "FAQ," https://docs.nats.io/reference/faq.
- Redis, "RedisTimeSeries," https://redis.io/docs/stack/timeseries/.
- Michael Nygard, Release It! (Raleigh: Pragmatic Bookshelf, 2007), 96.
- Unlaunch, "Client-side and Server-side SDKs," https://docs.unlaunch.io/docs/sdks/client-vs-server-side-sdks.
- Malcolm Featonby, "Making retries safe with idempotent APIs," https://aws.amazon.com/builders-library/making-retries-safe-with-idempotent-APIs/.






